
🔍 検索テストとは
ファイル解析完了後、「検索テスト」ページでデータセットの検索精度を確認し、最適な設定に調整することができます。 実際にユーザーが入力しそうな質問を投げかけ、期待通りのドキュメントがヒットするかを確認しましょう。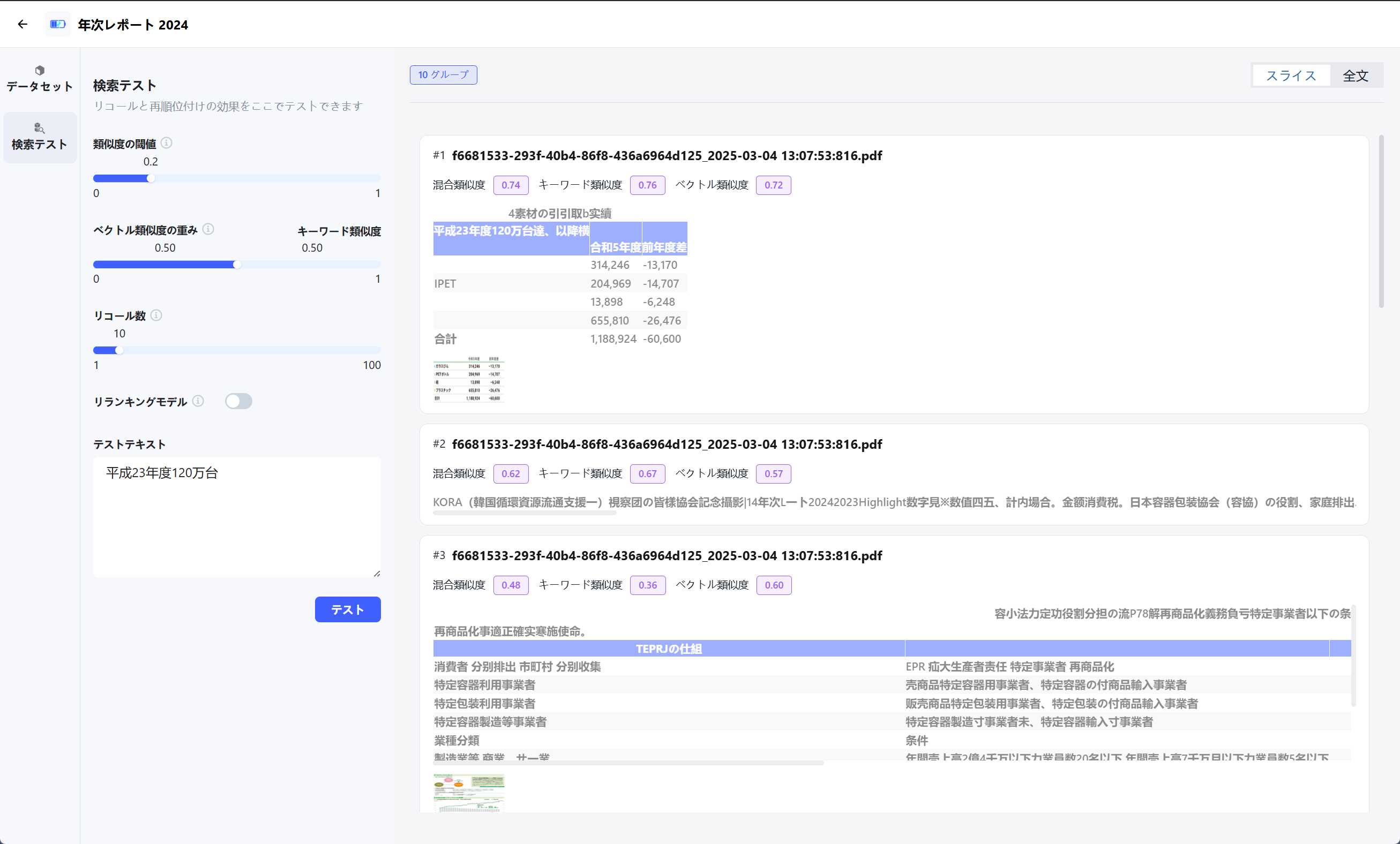
🧪 テスト手順
⚙️ パラメータ設定
検索精度をチューニングするための重要な設定項目です。類似度しきい値
「どれくらい似ている情報を拾うか」の基準値です。
- 高い値 (0.7~): 確実に関連する情報だけを厳選します(取りこぼしが増える可能性あり)。
- 低い値 (~0.5): 関連性が薄い情報も広く拾います(ノイズが増える可能性あり)。
ベクトル検索の影響度
「キーワード一致」と「意味の類似」のバランスを調整します。
- 1.0 (デフォルト): ベクトル検索(意味の類似)のみを使用。
- 値を下げる: キーワード検索(完全一致)の比重が増えます。固有名詞や型番などを検索する場合に有効です。
検索結果数 (Top K)
取得する情報の最大件数です。
- 多くの情報を参照させたい場合は増やしますが、多すぎるとLLMが混乱する原因になります(通常は3〜5件推奨)。
検索結果の最適化 (Rerank)
検索結果をAIが再評価して並び替える機能です。
- ON: 精度が向上しますが、処理に少し時間がかかります。
- OFF: 高速ですが、順位付けの精度は標準的です。