リンクを抽出
一覧ページから対象記事の URL を正規表現で抽出します。
本文を取得
抽出した各記事ページからタイトル、本文、公開日を取得します。
ナレッジ化
取得結果を Agent で整形し、ナレッジベースへ保存します。
Webスクレイピングの基本ロジック
Webスクレイピングツールは、ツール画面から公式ツールとして作成・利用できます。典型的な利用シーンは、複数のタイトルやリンクを含む一覧ページから対象ページを抽出し、それぞれの詳細ページにある必要な情報を取得するケースです。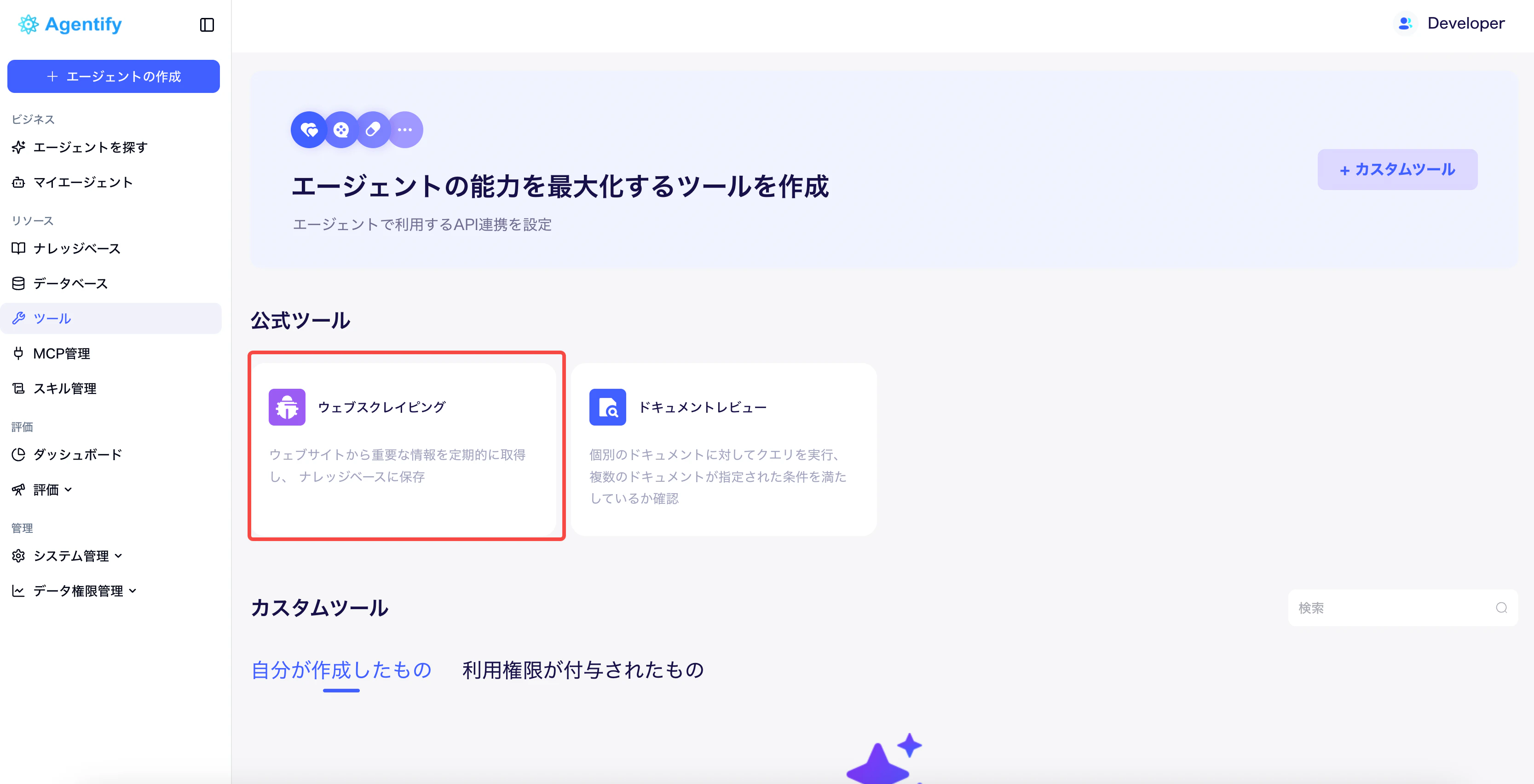
1. 新しいスクレイピングタスクを作成する
Agentify にログインし、左側メニューから「ツール」>「公式ツール」>「Webスクレイピング」を開きます。画面右上の「新規タスクの確認」から、新しいスクレイピングタスクを作成します。
2. スクレイピング設定
2.1 取得対象ページを設定する
まず、情報源となる Web ページの URL を決めます。この URL は、複数の記事タイトルやリンクを含む一覧ページである必要があります。 本ガイドでは、PR TIMES の AI キーワードページを例にします。prtimes-news のような名前を付けます。入力後、「次へ」をクリックしてフィールド設定へ進みます。
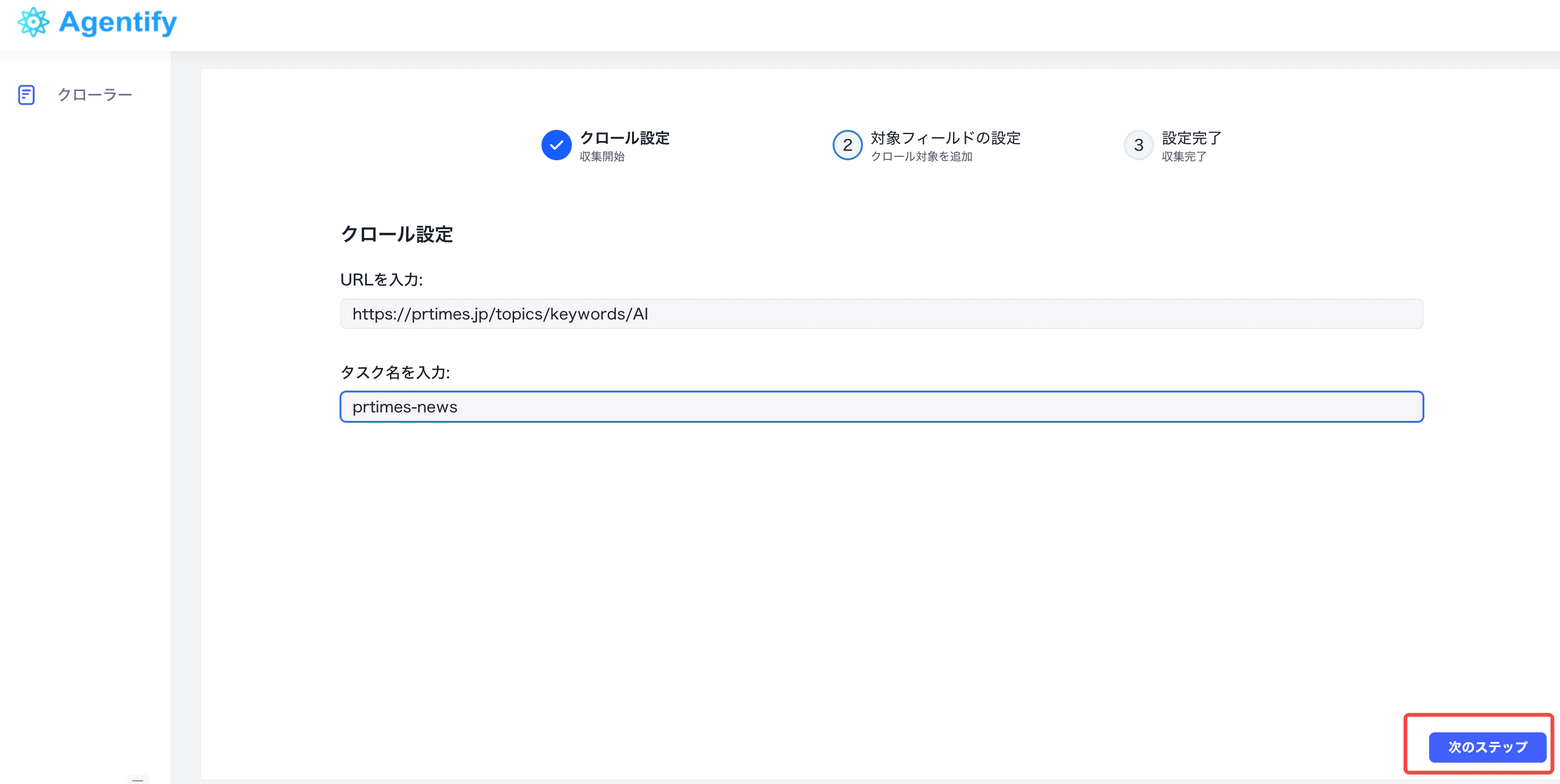
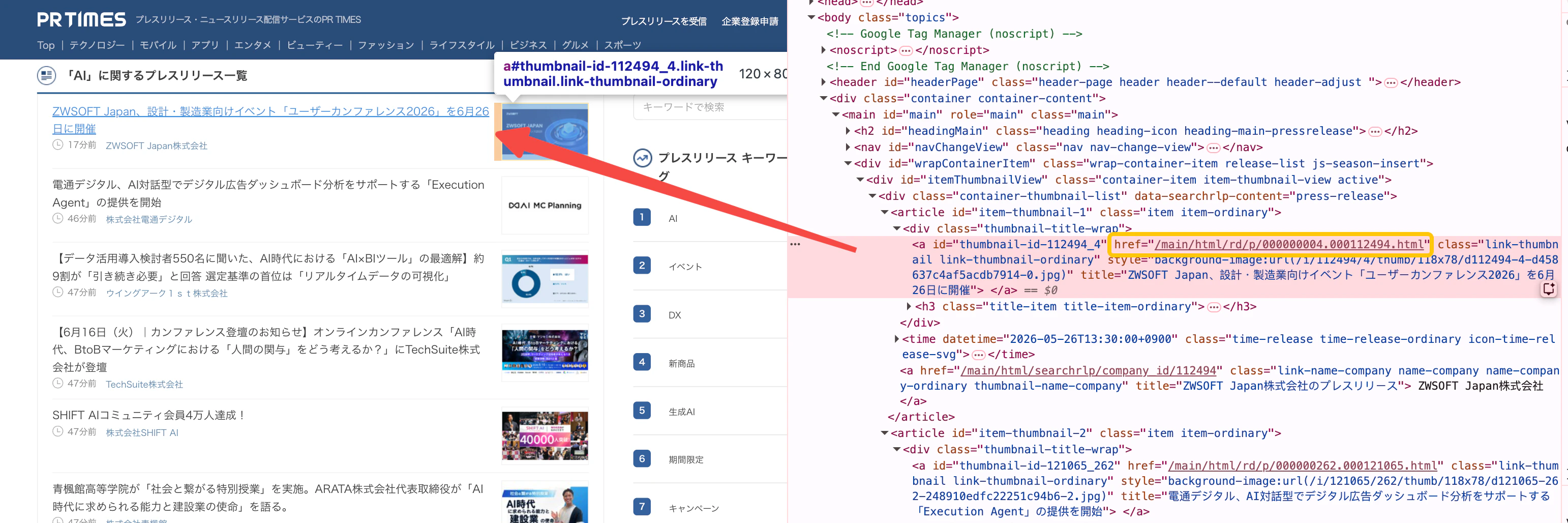
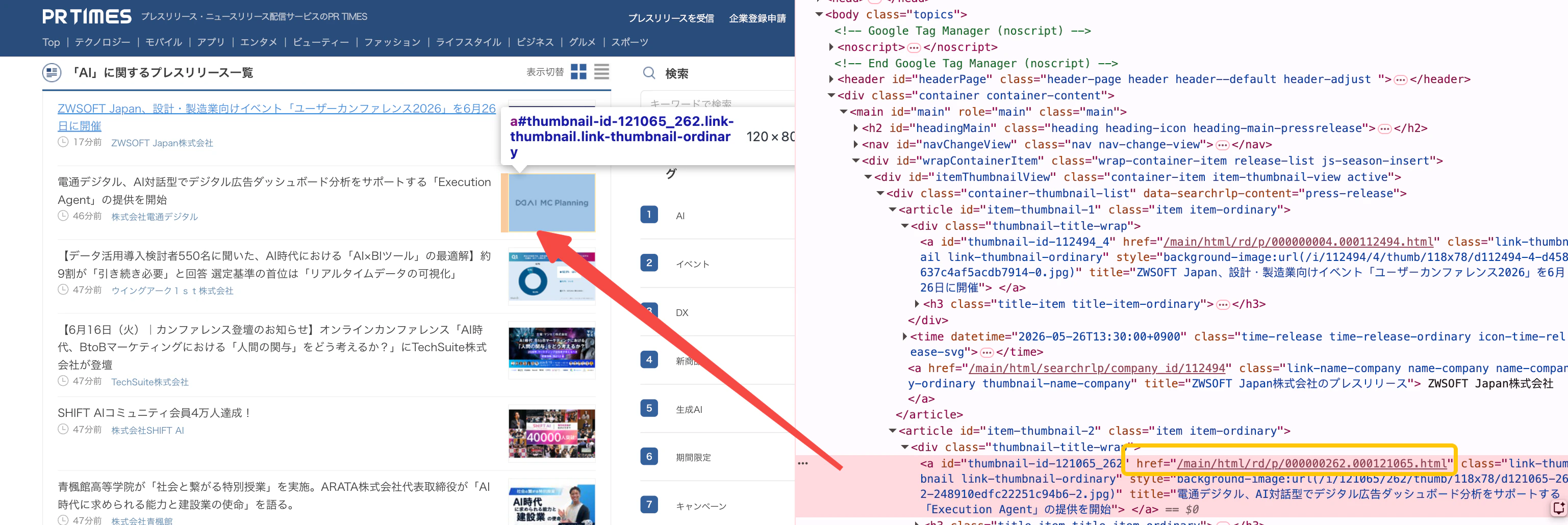
2.2 記事リンクを抽出する
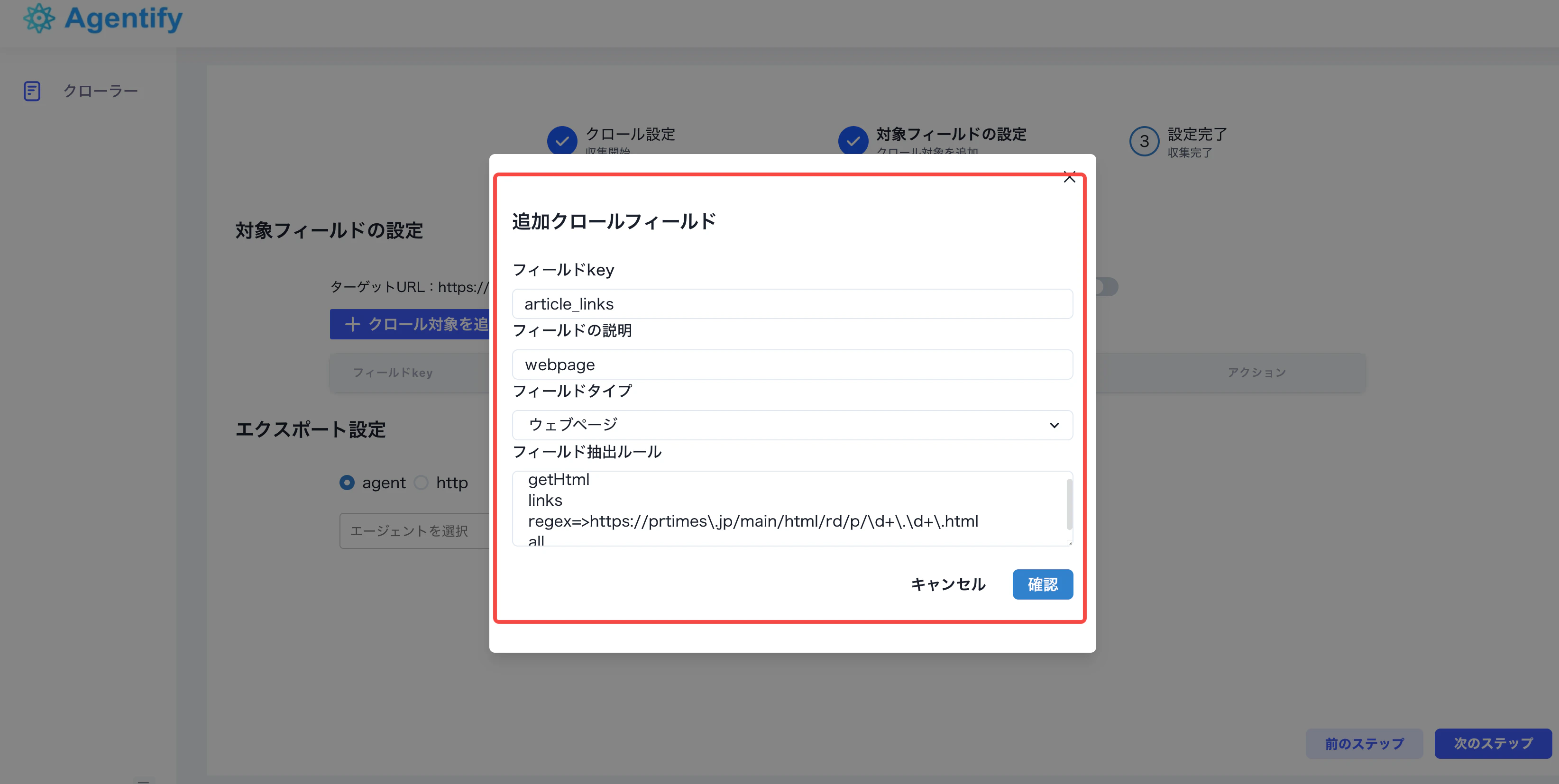
最初のフィールドでは、一覧ページから取得対象の記事リンクを抽出します。対象 URL には多くのリンクが含まれるため、記事ページの URL パターンを確認し、正規表現で必要なリンクだけを絞り込みます。フィールド key
article_links を設定します。正規表現で抽出した記事リンク一覧を表す key です。フィールド説明
Webページ など、抽出内容が分かる説明を設定します。フィールドタイプ
リンクを抽出するため、フィールドタイプは
Webページ を選択します。抽出ルール
getHtml、links、regex、all を組み合わせて対象 URL を抽出します。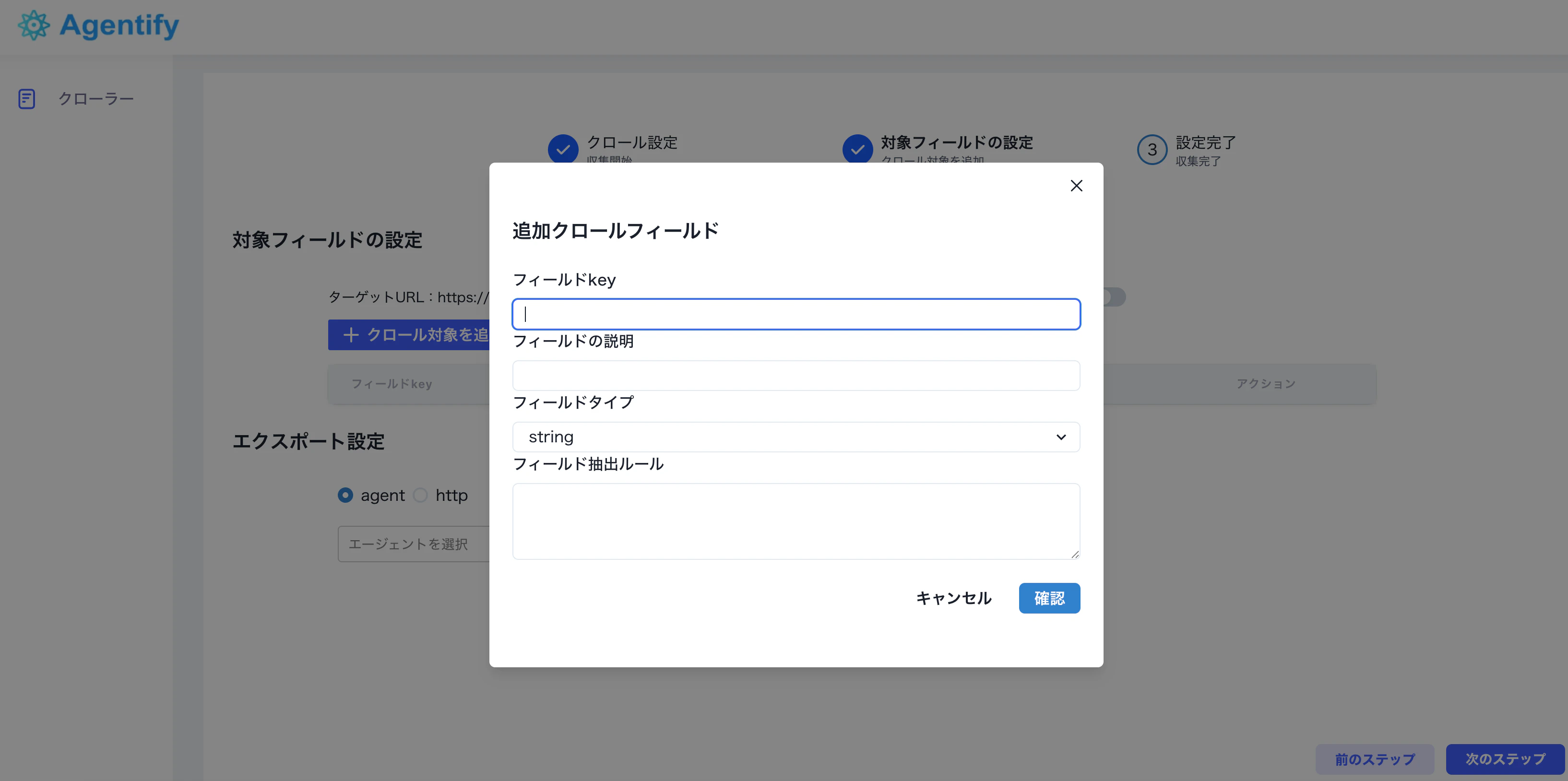
/main/html/rd/p/xxxxx.xxxxx.html の形式を含むため、以下のルールを設定します。
2.3 記事ページ内のフィールドを取得する
article_links のフィールドタイプを Webページ にすると、リンク先ページに対して追加フィールドを設定できます。「Webページ」の横にある「取得」をクリックし、記事詳細ページから必要な情報を取得します。
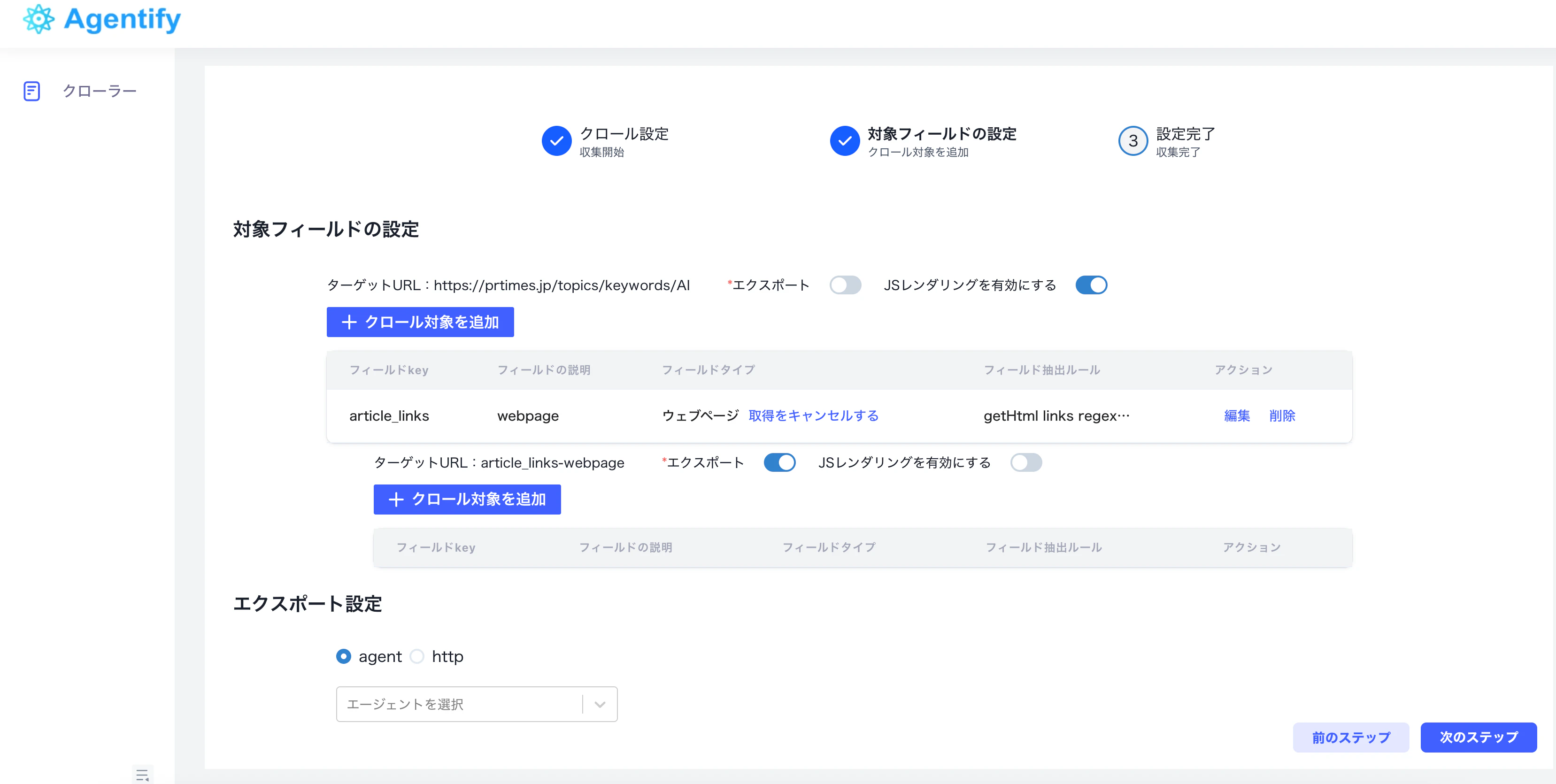
- 記事タイトル
- 記事本文
- 公開日
article_links の下にフィールドを追加し、key を title、フィールド説明を タイトル、フィールドタイプを string にします。抽出ルールは XPath を使って設定します。
XPath や regex の書き方は、クローラーマニュアル を参照してください。ページ構造の確認には AI を併用することもできます。
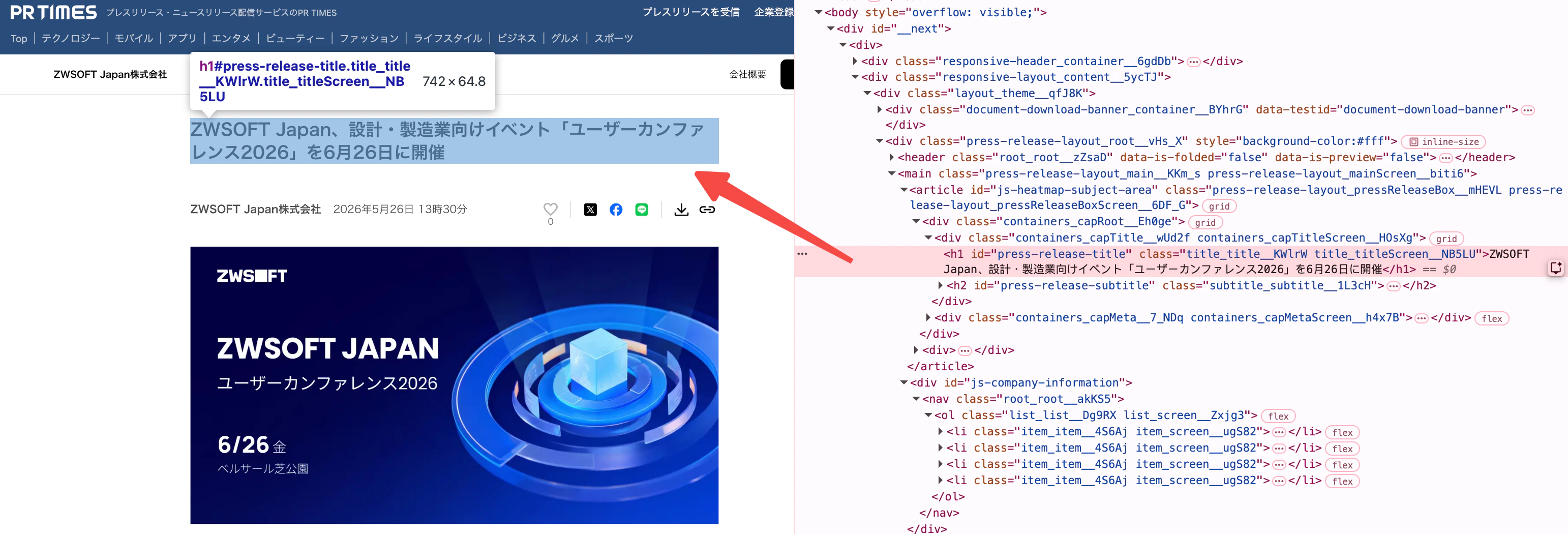
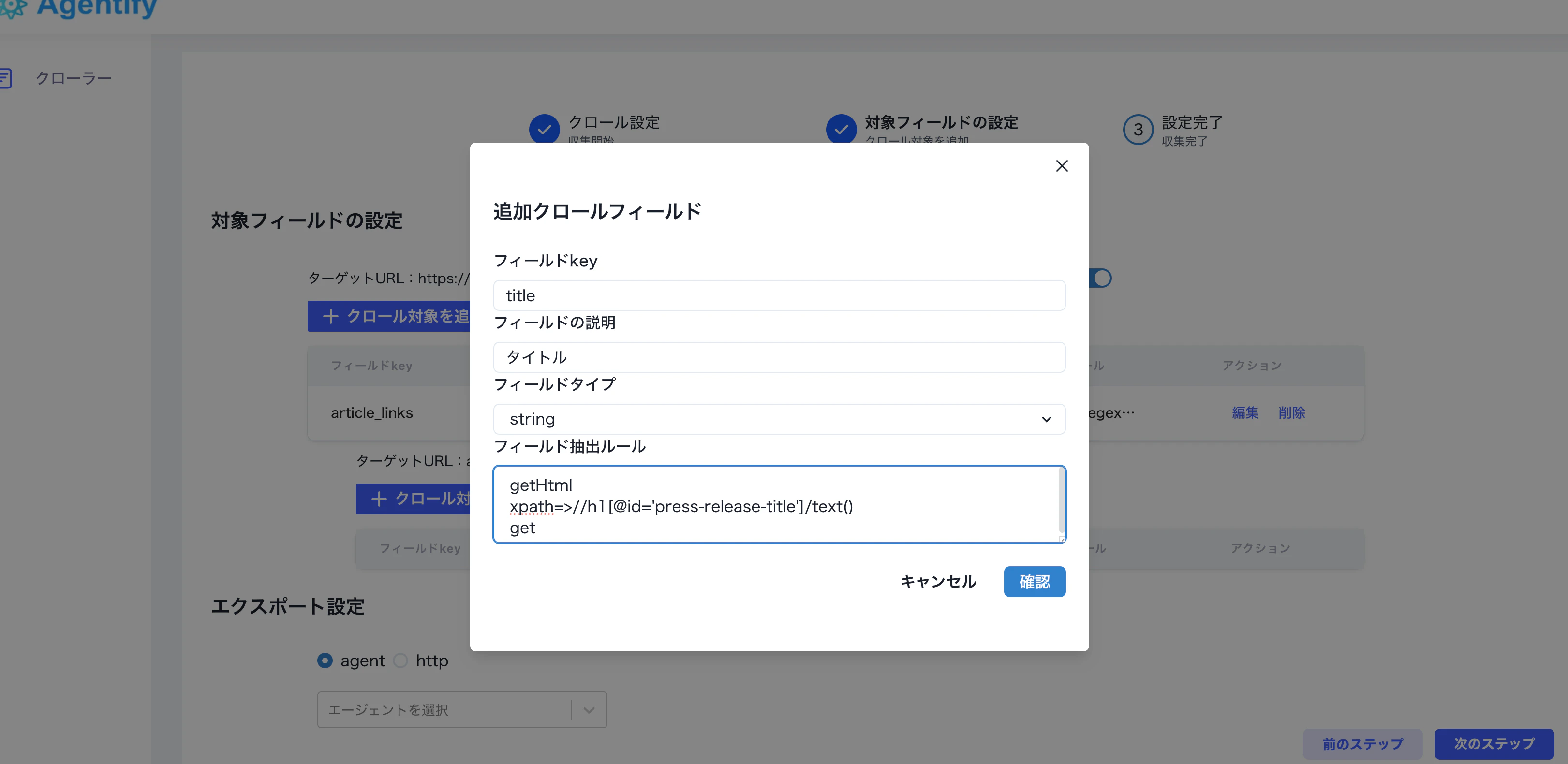
記事タイトルの抽出ルール
記事タイトルの抽出ルール
| 項目 | 設定値 |
|---|---|
| フィールド key | title |
| フィールド説明 | ニュースタイトル |
| フィールドタイプ | string |
記事本文の抽出ルール
記事本文の抽出ルール
| 項目 | 設定値 |
|---|---|
| フィールド key | press_release_body |
| フィールド説明 | ニュース本文 |
| フィールドタイプ | string |
公開日の抽出ルール
公開日の抽出ルール
| 項目 | 設定値 |
|---|---|
| フィールド key | published_at |
| フィールド説明 | 公開日 |
| フィールドタイプ | string |
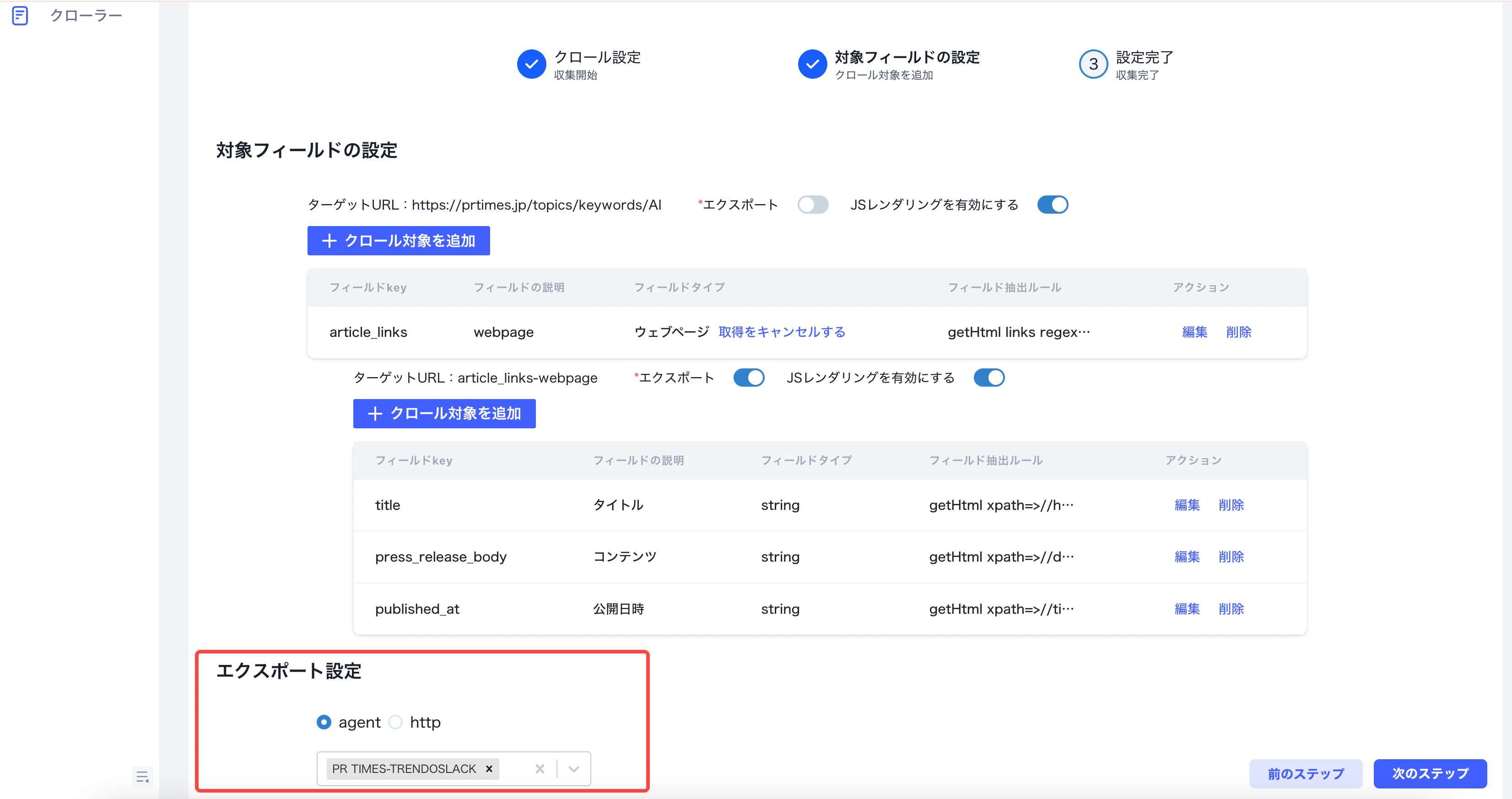
3. タスクを開始する
スクレイピングタスク一覧へ戻り、タスクを開始する前に定期取得の間隔を設定します。間隔は「分」「時間」「日」の単位で指定できます。設定後、「開始」をクリックするとタスクが実行されます。 実行後は、「取得リンク数」で対象ページが取得できているかを確認します。あわせて、連携先のナレッジベースに期待した形式で保存されているかも確認してください。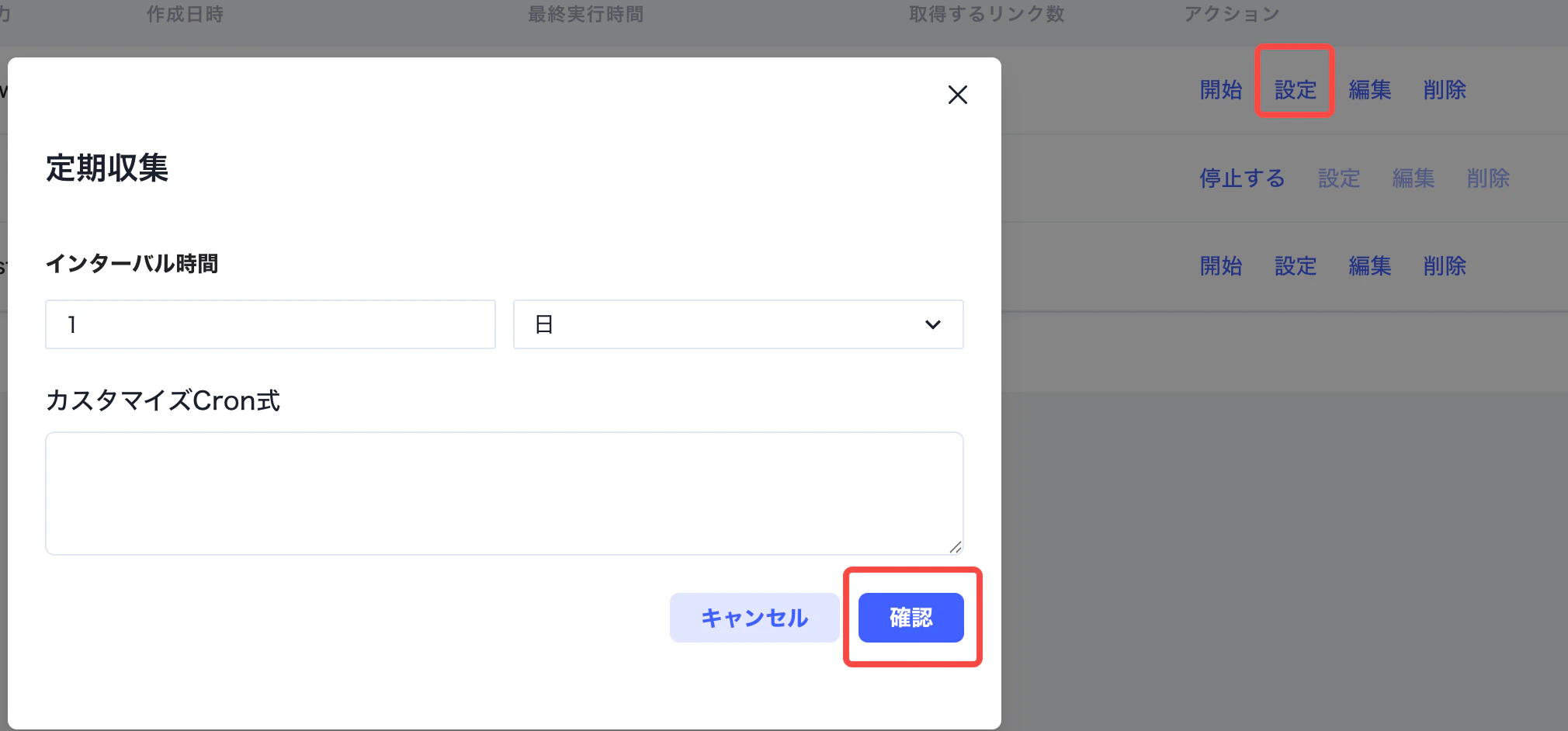

4. 連携 Agent の設計
スクレイピングでは、各記事ページから取得したtitle、press_release_body、published_at が key 名に対応する変数として Agent に渡されます。また、正規表現で抽出したリンク URL も変数として利用できます。
本ガイドでは、記事ごとに1つのナレッジベーススライスとして保存する構成を想定します。
スライス本文
記事本文
press_release_body を保存します。スライスタイトル
記事タイトル、URL、公開日を組み合わせて保存します。
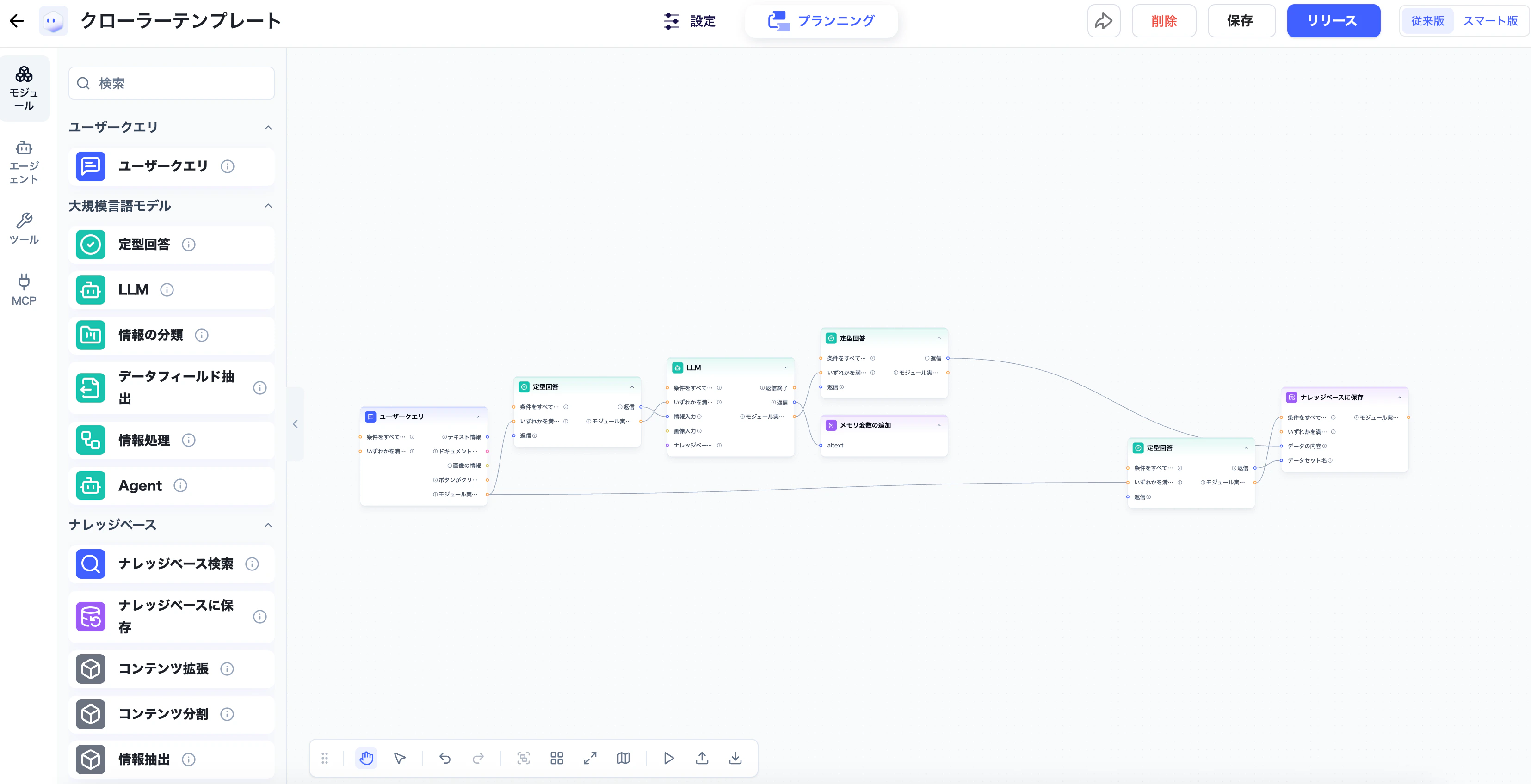
インポート用テンプレート
Agent プランニング画面でインポートできます。インポート後は「ナレッジベースに保存」モジュールの保存先を、自分のアカウントのナレッジベースへ変更してください。
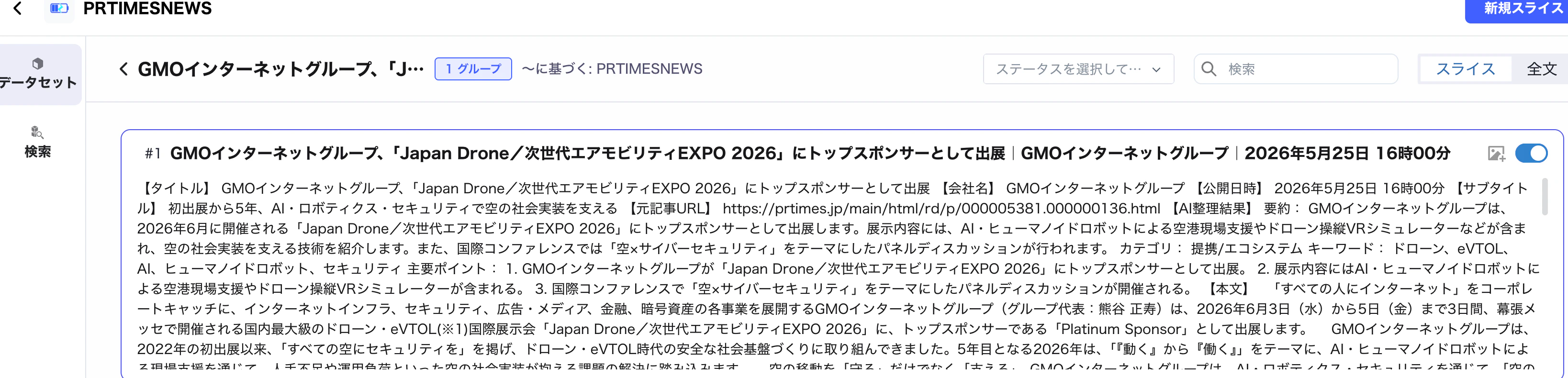
5. 結果を確認する
最後に、ナレッジベース内で取得した記事情報が想定通りに保存されているかを確認します。以下は保存結果の例です。