
モジュール概要
- ユーザーが画像をアップロードすると、AIの画像認識機能を活用し、画像に関する質問に回答します。
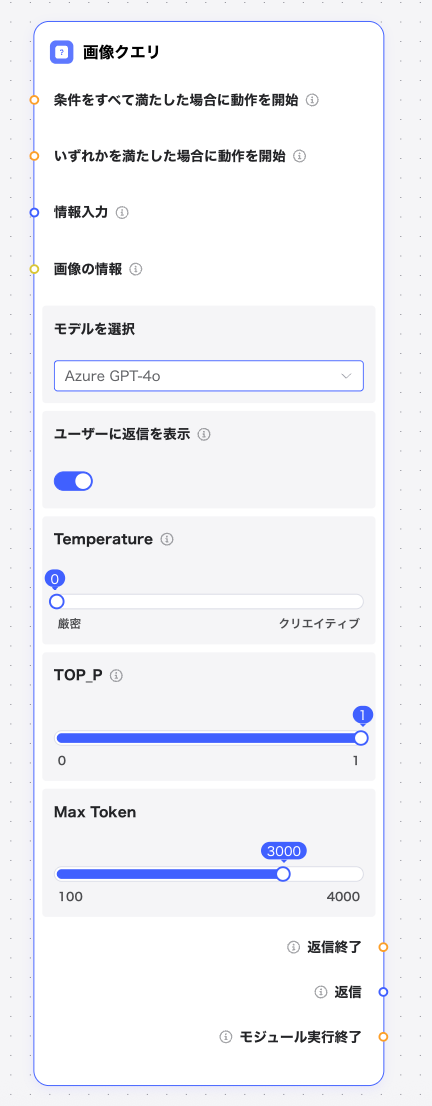
🔌 入力とトリガー (Inputs & Triggers)
条件をすべて満たした場合に動作を開始
タイプ: ブール型本ノードは複数のブール型入力を接続可能。全ての条件が
true の場合に本モジュールを実行します(AND条件)。いずれかを満たした場合に動作を開始
タイプ: ブール型本ノードは複数のブール型入力を接続可能。いずれか1つでも条件が
true の場合に本モジュールを実行します(OR条件)。情報入力
タイプ: 文字列型前処理の出力テキストをAIモデルに入力します。
画像情報
タイプ: 画像型「ユーザー入力」モジュールの「画像情報」から出力されたデータを受け取ります(PNG, JPG, JPEG, 最大30MB)。
⚙️ 設定 (Configuration)
モデルを選択
画像情報を処理するための AI画像認識モデルを選択します。
ユーザーに返信を表示
オフ時、モジュール処理は実行されますが、ユーザーチャット画面には表示されません(内部処理用)。
temperature(応答の創造性)
AI回答の自由度を調整します。数値が小さいほど厳密、大きいほど創造的な回答となります。
top_p(応答の多様性)
AI回答の多様性を調整します。数値が小さいほど多様性が低くなり、大きいほど多様性が高くなります。
max_tokens(応答文字数上限)
回答の最大文字数を制限します(使用AIモデルによって異なります)。
📤 出力と動作 (Outputs & Behavior)
返信終了
タイプ: ブール型すべての処理が完了すると
はい / いいえ を出力し、次のコンポーネントの実行条件として利用可能です。返信
タイプ: 文字列型AIが生成した回答を出力。次のモジュールの入力データとして使用することも可能です。
モジュール実行終了
タイプ: ブール型本モジュールの実行完了時、出力値は
True となります(通常、次処理を開始するためのトリガーとして使用)。